■ XPath
XPathは、次章で説明するXSLTで使用されるため、XML関連の仕様の中でもメジャーな言語です。仕様を理解するよりも、実際に使用してみるとすぐ理解できると思います。
以下、XPathについて説明します。
以下、XPathについて説明します。
| XPathとは | 軸とノードテスト |
| データモデル | 術部 |
| ロケーションパス | 主要関数 |
■ XPathとは
XPathとは、XML文章の中の要素や属性の位置を指定するための言語です。(XPath=
XML Path Language)
XPathは、XML文章をツリーとしてモデル化し、各ノード(要素や属性)への位置を指定できるようにします。また、指定したノードに対して、条件判定を行ったり、文字列計算をしたり、計算結果を使用したりすることも可能です。
XPathは、XML文章をツリーとしてモデル化し、各ノード(要素や属性)への位置を指定できるようにします。また、指定したノードに対して、条件判定を行ったり、文字列計算をしたり、計算結果を使用したりすることも可能です。
■ データモデル
XPathは、XMLのツリー構造をモデル化し、その中で属性や要素の位置を特定します。
例えば、以下のようなXMLのツリー構造があったとします。
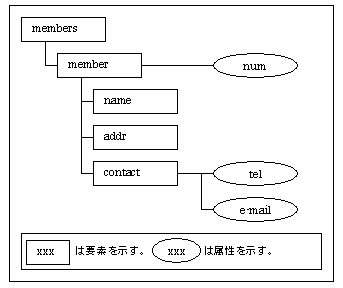
このツリーを、XPathは以下のノードに分類し管理します。(ノードとは扱うデータというような意味)
XPathで使用するノードには以下の種類があります。
例えば、以下のようなXMLのツリー構造があったとします。
このツリーを、XPathは以下のノードに分類し管理します。(ノードとは扱うデータというような意味)
- ルートノード
- 要素ノード
- 属性ノード
XPathで使用するノードには以下の種類があります。
| 種類 | 内容 |
| ルートノード | ツリーの一番上を示す。(一番上の要素ではない。仮想的な意味でのルートを指す。上の例では、ルートノードは、"/"と表現し、ルート要素は"/members"となる。) |
| 要素ノード | 要素を意味する。 |
| 属性ノード | 属性を意味する。 |
| テキストノード | 要素や属性の値を意味する。 |
| コメントノード | コメントを意味する。 |
| 処理命令ノード | 処理命令を意味する。 |
| 名前空間ノード | 名前空間を意味する。 |
■ ロケーションパス
XPathの表記は、”ロケーションパス”と”軸とノードテスト”で構成されます。
ロケーションパスは、UNIXやURLと似たような表記方法で"/"を区切りとしてノードパスを示していきます。(windowsのフォルダをイメージするとわかりやすいと思います。"\"="/"と考えてください。)
ロケーションパスでノードを区切り、軸とノードテストでそのノードが何かを示します。
ロケーションパスは、絶対表記と相対表記があり、絶対表記はルートノードから順に記述し、相対表記は、カレントからの位置関係を示します。
例を以下に示します。
[XML(単純・・)]
[絶対表記]
・Aの位置を指定
・Bの位置を指定
・Cの位置を指定
[相対表記]
カレントがBにあるとした場合。
・Aの位置を指定
・Bの位置を指定
・Cの位置を指定
ロケーションパスは、UNIXやURLと似たような表記方法で"/"を区切りとしてノードパスを示していきます。(windowsのフォルダをイメージするとわかりやすいと思います。"\"="/"と考えてください。)
ロケーションパスでノードを区切り、軸とノードテストでそのノードが何かを示します。
ロケーションパスは、絶対表記と相対表記があり、絶対表記はルートノードから順に記述し、相対表記は、カレントからの位置関係を示します。
例を以下に示します。
[XML(単純・・)]
<?xml version="1.0"?>
<A>
<B>
<C></C>
</B>
</A>
<A>
<B>
<C></C>
</B>
</A>
[絶対表記]
・Aの位置を指定
/a
・Bの位置を指定
/a/b
・Cの位置を指定
/a/b/c
[相対表記]
カレントがBにあるとした場合。
・Aの位置を指定
../
・Bの位置を指定
./
・Cの位置を指定
./c
■ 軸とノードテスト
ロケーションパスで説明しましたが、XPathでは、ロケーションパスでノードを区切り、軸とノードテストでそのノードが何かを示します。
軸は、ノードの方向を示し、例えば軸が"self"なら自分自身の階層を指し、軸が"parent"なら自分より一つ上の階層を意味します。ノードテストは、そのノードの意味を示し、例えば、コメントノードであれば、"comment()"で表現します。軸とノードの表記の仕様は以下のようになります。
ノードテストの一覧を示します。
この軸とノードテストは、通常略記で示されます。以下、主要な略記と内容を示します。
memberに基準(カレント)があるものとします。(後述の述部が指定されていないため、当てはまるノード全てが示される位置となります。)
軸は、ノードの方向を示し、例えば軸が"self"なら自分自身の階層を指し、軸が"parent"なら自分より一つ上の階層を意味します。ノードテストは、そのノードの意味を示し、例えば、コメントノードであれば、"comment()"で表現します。軸とノードの表記の仕様は以下のようになります。
| 軸 | :: | ノードテスト |
軸の一覧を示します。
| 軸 | 内容 |
| self | 基点ノード |
| child | 基点ノードの子 |
| parent | 基点ノードの親 |
| ancestor | 基点ノードの祖先(親も含む) |
| ancestor-or-self | 基点ノードの祖先(自分も含む) |
| following-sibling | 基点ノードの兄弟で基点ノードの後で出てくる |
| preceding-sibling | 基点ノードの兄弟で基点ノードの前で出てくる |
| following | 基点ノードの後で出てくる |
| precedin | 基点ノードの前で出てくる |
| attribute | 基点ノードの属性 |
| descendant-or-self | 基点ノードの子孫 |
| namespace | 基点ノードの名前空間 |
ノードテストの一覧を示します。
| ノードテスト | 内容 |
| 名前 | 要素や属性ノードを示す。 |
| text() | テキストノードを示す。 |
| node() | 要素や属性を明示的に指す。 |
| * | 軸の子ノード全て。 |
| comment() | コメントノードを指す。 |
| processing-instruction() | 処理命令ノードを指す。 |
この軸とノードテストは、通常略記で示されます。以下、主要な略記と内容を示します。
| 略記 | 正式 |
| 要素 | child::node() |
| * | child::* |
| . | self::node() |
| .. | parent::node() |
| //要素 | descendant-or-self::要素 |
| 要素元//要素 | 要素元/descendant-or-self::node()/要素 (要素元以下の、要素で示される名前の要素全て) |
| @属性 | attribute::属性 |
| @* | attribute::* |
以下のXMLを例に、それぞれの略記が示すノードをサンプルとして記述しておきます。
<?xml version="1.0"?>
<members>
<member num="01">
<name>山田太郎</name>
<addr>東京都XXXXX</addr>
<contact tel="03-xxxx-xxxx" e-mail="xx@xxxxx" />
</member>
<member num="02">
<name>山田花子</name>
<addr>大阪府XXXX</addr>
<contact tel="06-xxxx-xxxx" />
</member>
</members>
<members>
<member num="01">
<name>山田太郎</name>
<addr>東京都XXXXX</addr>
<contact tel="03-xxxx-xxxx" e-mail="xx@xxxxx" />
</member>
<member num="02">
<name>山田花子</name>
<addr>大阪府XXXX</addr>
<contact tel="06-xxxx-xxxx" />
</member>
</members>
memberに基準(カレント)があるものとします。(後述の述部が指定されていないため、当てはまるノード全てが示される位置となります。)
| 例 | 示される位置 |
| ./name | name要素 (山田太郎と山田花子の要素) |
| ./* | name要素、addr要素、contact要素 (山田太郎、東京都XXXXX、contact要素、山田花子、大阪府XXXX、contact要素 ) |
| . | member要素 (num="01"とnum="02"の要素) |
| .. | members要素 |
| members//name | name要素 (山田太郎と山田花子の要素) |
| //name | name要素 (山田太郎と山田花子の要素) |
| ./@num | num属性 (num="01"とnum="02") |
| ./contact/@* | tel属性、e-mail属性 (tel="03-xxxx-xxxx" e-mail="xx@xxxxx"tel="06-xxxx-xxxx" ) |
■ 術部
以下のようなXMLがあったとします。
このツリー構造は以下のようになっているとします。
このXMLで、"山田花子"というデータの位置を示したいと思います。
というXPathでは、member要素の下のname要素全てを意味するため、山田太郎、山田花子の2つのノードを意味してしまいます。
そこで、XPathでは要素の絞込みを行うために述部を用意しています。術部の仕様は以下の通りです。
でデータ位置を指定できます。(self::node()は略記でもよい。その場合".='山田花子'"と記述する。)
また、述語は出現の順序でも表現できます。山田花子は、name要素の上から2番目に位置しています。この場合、以下の記述も可能です。
<?xml version="1.0"?>
<members>
<member num="01">
<name>山田太郎</name>
<addr>東京都XXXXX</addr>
<contact tel="03-xxxx-xxxx" e-mail="xx@xxxxx" />
</member>
<member num="02">
<name>山田花子</name>
<addr>大阪府XXXX</addr>
<contact tel="06-xxxx-xxxx" />
</member>
</members>
<members>
<member num="01">
<name>山田太郎</name>
<addr>東京都XXXXX</addr>
<contact tel="03-xxxx-xxxx" e-mail="xx@xxxxx" />
</member>
<member num="02">
<name>山田花子</name>
<addr>大阪府XXXX</addr>
<contact tel="06-xxxx-xxxx" />
</member>
</members>
このツリー構造は以下のようになっているとします。
このXMLで、"山田花子"というデータの位置を示したいと思います。
/members/member/name
というXPathでは、member要素の下のname要素全てを意味するため、山田太郎、山田花子の2つのノードを意味してしまいます。
そこで、XPathでは要素の絞込みを行うために述部を用意しています。術部の仕様は以下の通りです。
| 軸 | :: | ノードテスト | [式] |
上記の例では、
/members/member/name[self::node()='山田花子']
でデータ位置を指定できます。(self::node()は略記でもよい。その場合".='山田花子'"と記述する。)
また、述語は出現の順序でも表現できます。山田花子は、name要素の上から2番目に位置しています。この場合、以下の記述も可能です。
/members/member/name[2]
式で使用できる演算子は以下のものがあります。
(XMLやXSLTでXPathを使用する場合、"<"や">"はエンティティ参照しなくてはいけないことに注意してください。)
| 比較演算子 | 内容 |
| = | 等しい |
| != | 等しくない |
| < | より大きい |
| <= | 以上 |
| > | より小さい |
| >= | 以下 |
| or | 左辺と右辺が偽の場合、偽。 |
| and | 左辺と右辺が真の場合、真。 |
| 数値演算 | 内容 |
| + | 足し算 |
| - | 引き算 |
| * | 掛け算 |
| div | 割り算 |
| mod | 割り算の余り |
式の中には、関数を使用することも可能です。(主要関数を後述。)
以下、述部のサンプルを幾つか示します。(上記例のXMLを使用します。)
・山田花子の電話番号
/members/member/name[.='山田花子']/contact/@tel
・電話番号が'06-xxxx-xxxx'の人の名前
/members/member/name[contact/@tel='06-xxxx-xxxx']
・電話番号に03が付く人の名前(contain関数使用)
/members/member/name[contain(contact/@tel,'03']
■ 主要関数
述部で使用可能な主要関数を示します。
関数: number count(node-set)
関数: number count(node-set)
node-setのノードの数を返す。
関数: number last()
ノードの数を返す。
例えば、name[last()]でname要素の一番最後の要素を指す。
関数:number position()
ノードの位置を返す。
例えば、name[posiotion()=2]でname要素の2番目の要素を指す。
関数: number sum(node-set)
sum 関数は、引数 node-set
の各ノードについてそのノードの文字列値を数値に変換した結果の合計を返す。
関数: boolean start-with(string,string)
第1引数が第2引数から始まる場合、真を返す。
関数: boolean contain(string,string)
第1引数の文字列中に第2引数の文字列がある場合場合、真を返す。
関数: number string-length(string)
引数の文字列長を返す。